Tal y como se ha definido en el ciclo de vida de eXtreme Programming la primera fase es la exploración, fase en la que se plantean las historias de usuario (user stories) al mismo tiempo que el equipo de desarrollo se familiariza con las herramientas, tecnologías y prácticas que se utilizarán en el proyecto. Se prueba la tecnología y se exploran las posibilidades de la arquitectura del sistema construyendo un prototipo.
Las historias de usuario son la técnica utilizada en XP para especificar los requisitos del software, lo que equivaldría a los casos de uso en el proceso unificado.
Se describen brevemente las características que el sistema debe tener desde la perspectiva del cliente, en este caso hay tres grupos de funcionalidades bien diferenciadas: gestión de clientes y proveedores, gestión de inventario y gestión de compras y ventas.
Como requisitos generales del sistema se consideran principalmente auditoría, seguridad y la accesibilidad desde dispositivos móviles.
Los cambios realizados al sistema por los usuarios deben ser auditados. Para todas las altas, modificaciones y eliminaciones de datos se debe conocer el qué, quién y cuándo se han realizado.
Existirán varios roles de usuarios, y cada uno de ellos sólo podrá acceder a un subconjunto de los datos y las operaciones. Existirá un usuario administrador que tendrá acceso completo a la aplicación.
En este apartado se tratará el concepto de contacto (party), persona u organización que es la otra parte en una relación comercial.
Cada uno de estos contactos puede tiene como atributo un nombre interno, que es el utilizado comúnmente para referirse a él, y unos atributos según sea:
persona
título (Sr., Sra.)
nombre
apellidos
organización
nombre oficial
Además de esto pueden tener información para contactar con ellos, como pueden ser:
direcciones postales (destinatario, dirección, ciudad, código postal, provincia, país)
números de teléfono (país, código de área, teléfono, extensión)
direcciones de correo electrónico (e-mail)
direcciones web (url)
Cada uno de ellos con el propósito de esa información de contacto, por ejemplo
correo electrónico del departamento de ventas
dirección del almacén
dirección de las oficinas
etc.
Para la creación de un contacto el usuario debe seleccionar si es una persona o una organización, y según su elección introducir los atributos correspondientes.
Al usuario se le muestran los atributos correspondientes al tipo de contacto y la lista con las informaciones de contacto.
Cuando se considere que ya no son de relevancia los clientes o proveedores podrán ser borrados.
Se podrán realizar búsquedas por cualquiera de los atributos, tanto de personas como de organizaciones.
Desde la visualización de un contacto se podrá añadir información de contacto, seleccionando el tipo de información (dirección postal, número de teléfono, correo electrónico o dirección web) se permitirá que el usuario introduzca los atributos correspondientes.
Se mostrará el tipo de información, sus atributos y los propósitos de ella.
Se podrán cambiar los atributos de cualquier tipo de información de contacto.
La gestión de inventario se centra en las operaciones con modelos (models) y productos (products). Esta es una de las partes más complicadas en cualquier empresa, ya que se tiene que tratar con productos procedentes de diversos proveedores, que llaman de distintas formas a la misma cosa, que tienen unos procesos muy distintos unos a otros,...
En el negocio textil esto es más complicado si cabe, donde apenas se utilizan los pocos estándares que existen, no se utiliza la misma nomenclatura para los tallajes ni los colores y el uso de códigos de barras es inferior al 50%, por lo que aproximaciones que habitualmente son usadas en otro tipo de negocios no son aplicables.
Volviendo a modelos y productos, los modelos representan un diseño concreto, del que pueden existir distintas tallas y colores. Los modelos son exclusivos de cada proveedor, es decir dos proveedores nunca hacen un mismo modelo, siempre hay alguna diferencia como puede ser la calidad del tejido. Los modelos tienen los siguientes atributos:
código de modelo del proveedor
nombre, asignado por la empresa, que normalmente será el código asignado por el proveedor, pero que podría ser cambiado si ya existiese ese código anteriormente o el proveedor no asignara ninguno.
descripción
año
temporada, principalmente
permanente
primavera-verano
otoño-invierno
tallaje
recién nacido (000, 00, ..., 30, 36)
niño (1, 2, ..., 8, 10)
niño mayor (4, 6, ..., 16, 18)
caballero (48, 50, ..., 58, 60)
señora (5, 6, 7, 8)
Cada modelo tiene productos, que son la representación de cada talla y color, con su SKU (Stock Keeping Unit) que es el identificador que se utilizará para referirse a ellos dentro de la empresa, y la posibilidad de tener un número ilimitado de códigos de barras, para evitar los problemas causados por la posible gestión incorrecta de los proveedores.
Se considera la posibilidad de que la empresa tenga más de un almacén, si bien esto no es lo habitual, con lo que en cada uno de ellos podría existir stock de los productos.
También se considera que pueden existir varias tarifas, cada una con un precio distinto para cada producto.
Par crear un modelo el usuario debe seleccionar el proveedor al que pertenece, introducir el código del modelo del proveedor, el nombre, la descripción, el año, la temporada, el tallaje al que pertenece y seleccionar los colores en los que lo habrá. Automáticamente se crearán los productos correspondientes a cada talla del tallaje y a cada color seleccionado.
La visualización de un modelo consistirá en mostrar sus atributos así como cada uno de sus productos, con su talla, color, stock en cada uno de los almacenes, precio en cada tarifa y sus códigos de barras.
Borrar un modelo equivale a darlo de baja porque ni se dispone de stock ni se dispondrá en el futuro.
Se podrá buscar un modelo por cualquiera de sus atributos, cuyo resultado será una lista de modelos desde la que poder ir a la visualización de cada uno de ellos.
Dentro de esta funcionalidad se engloba el proceso de creación de
pedidos (orders)
albaranes (delivery dockets)
facturas (invoices)
tanto para compras como para ventas.
El proceso de ventas comienza cuando un representante visita a un cliente en su lugar de negocio. Este cliente escoge una serie de productos y cantidades que se formalizan en un pedido.
Posteriormente los pedidos son servidos según se considere oportuno. Se podrán servir en su totalidad o parcialmente, quedando pendientes las cantidades no servidas para posteriores ocasiones, pudiendo también servir en un único envío mercancía de más de un pedido. Se generará un albarán con la mercancía enviada, corresponda a uno o varios pedidos, es decir si se sirve mercancía de dos pedidos en un único envío se generará un único albarán.
Finalmente se generarán las facturas a partir de los albaranes, pudiendo una factura incluir varios albaranes. Normalmente estas facturas se incluyen en los envíos por lo que sólo se incluirá el albarán correspondiente.
El proceso de compra es exactamente el mismo.
A partir de un cliente o proveedor se podrá crear un nuevo pedido, seleccionando si se trata de un pedido de compra o de venta. El único dato necesario será la fecha del pedido, que normalmente será el mismo día, y se podrán anotar cualquier tipo de comentarios.
Se podrán buscar los productos para añadirlos al pedido en curso, en la cantidad deseada.
Al visualizar un pedido se mostrarán los datos del cliente o proveedor y la lista de productos.
La fecha o los comentarios del pedido pueden ser modificados, así como la lista de productos, pudiendo añadir, quitar o modificar las cantidades de éstos.
La lista de pedidos pendientes debe estar accesible, preferiblemente con un indicador sobre la posibilidad de ser servido parcial o totalmente.
Crear un albarán implica seleccionar de entre los pedidos pendientes de un cliente o proveedor la mercancía que es servida, seleccionando las cantidades que se servirán de cada producto, normalmente el total.
En el desarrollo de este proyecto se han utilizado las siguientes herramientas en cada ámbito. Todo el software utilizado es gratuito y tan sólo la herramienta Poseidon no es open source.
Java™ 2 SDK, Standard Edition 1.4.2-04 Sun Microsystems
Jikes java compiler 1.20 para una compilación más rápida.
Poseidon for UML Community Edition 2.4.1 para la realización de diagramas UML
Eclipse IDE SDK 3.0 con los siguientes plugins:
Spring IDE plugin for Eclipse 1.0.1 para la integración de Spring Framework en el IDE
Mevenide 0.2.1 para la integración con Maven
Sysdeo Eclipse Tomcat Launcher plugin 2.2 para la integración con Tomcat permitiendo la depuración de código en el servidor.
CVS (Concurrent Versions System) CVSNT 2.0.2
PuTTY 2004-08-08 cliente SSH
Se utiliza Maven 1.0 para la gestión integral del proyecto, todo lo necesario está explícitamente especificado en el descriptor de proyecto de Maven.
El software requerido para la ejecución del sistema es:
Un servidor de aplicaciones web (Tomcat, Jetty,...)
Un sistema gestor de base de datos relacional (MySQL, PostgreSQL, Oracle, ...)
Un navegador web (Internet Explorer, Mozilla, Netscape Navigator, Opera, ...)
Este es el software que ha sido utilizado para la ejecución y los tests del sistema para cada uno de los roles anteriores.
Servidor de aplicaciones web
Jakarta Tomcat 5.0.25
Base de datos
MySQL 4.0.13-Max bajo Windows
MySQL 4.0.15-Max bajo Linux
PostgreSQL 7.4.5 bajo Cygwin en Windows
MS SQL 2000
HSQLDB 1.7.2, esta versión NO es compatible con el software dado que no soporta niveles de aislamiento entre transacciones.
Navegadores web
Internet Explorer 6
Mozilla Firefox 0.8
PalmOS Garnet Simulator 5.4 + PalmSource Web Browser 2.0 SDK for Palm OS Garnet para comprobar los resultados en una PDA con el sistema operativo PalmOS
Lo novedoso de las tecnologías usadas es uno de los puntos fuertes de este proyecto. Todas ellas son tecnologías Java open source. El aprendizaje y familiarización ha ocupado la mayor parte del tiempo del proyecto.
Maven es una herramienta de gestión de información de proyectos. Maven está basado en el concepto de un modelo de objetos del proyecto POM (Project Object Model) en el que todos los productos (artifacts) generados por Maven son el resultado de consultar un modelo de proyecto bien definido. Compilaciones, documentación, métricas sobre el código fuente y un innumerable número de informes son todos controlados por el POM.
Maven tiene muchos objetivos, pero resumiendo Maven intenta hacer la vida del desarrollador sencilla proporcionando una estructura de proyecto bien definida, unos procesos de desarrollo bien definidos a seguir, y una documentación coherente que mantiene a los desarrolladores y clientes informados sobre lo que ocurre en el proyecto. Maven aligera en gran cantidad lo que la mayoría de desarrolladores consideran trabajo pesado y aburrido y les permite proseguir con la tarea. Esto es esencial en proyectos open source donde no hay mucha gente dedicada a la tarea de documentar y propagar la información crítica sobre el proyecto que es necesaria para atraer potenciales nuevos desarrolladores y clientes.
La ambición de Maven es hacer que el desarrollo interno del proyecto sea altamente manejable con la esperanza de proporcionar más tiempo para el desarrollo entre proyectos. Se puede llamar polinización entre proyectos o compartir el conocimiento sobre el desarrollo del proyecto.
Características:
El modelo de objetos del proyecto POM es la base de cómo Maven trabaja. El desarrollo y gestión del modelo está controlado desde el modelo del proyecto.
Un único conjunto de métodos son utilizados para todos los proyectos que se gestionan. Ya no hay necesidad de estar al tanto de innumerables sistemas de compilación. Cuando las mejoras se hacen en Maven todos los usuarios se benefician.
Integración con Gump, una herramienta usada en el proyecto Jakarta para ayudar a los proyectos a mantener compatibilidad con versiones anteriores.
Publicación del sitio web basado en el POM. Una vez el POM es exacto los desarrolladores pueden publicar fácilmente el contenido del proyecto, incluyendo la documentación personalizada más el amplio conjunto de documentación generada por Maven a partir del código fuente.
Publicación de distribuciones basada en el POM.
Maven alenta el uso de un repositorio central de librerías, utilizando un mecanismo que permite descargar automáticamente aquellas necesarias en el proyecto, lo que permite a los usuarios de Maven reutilizar librerías entre proyectos y facilita la comunicación entre proyectos para asegurar que la compatibilidad entre distintas versiones es correctamente tratada.
Guías para la correcta disposición de los directorios. Maven contiene documentación sobre como disponer los directorios de forma que una vez es aprendida se puede ver fácilmente cualquier otro proyecto que use Maven.
La Programación Orientada a Aspectos, más conocida como AOP por su nombre en inglés Aspect Oriented Programming, es un modelo de programación que aborda un problema específico: capturar las partes de un sistema que los modelos de programación habituales obligan a que estén repartidos a lo largo de distintos módulos del sistema. Estos fragmentos que afectan a distintos módulos son llamados aspectos y los problemas que solucionan, problemas cruzados (crosscutting concerns).
Usando un lenguaje que soporte AOP, podemos capturar estas dependencias en módulos individuales, obteniendo un sistema independiente de ellos y podemos utilizarlos o no sin tocar el código del sistema básico, preservando la integridad de las operaciones básicas.
Los principales campos de aplicación de la AOP son:
rastreo de la ejecución (tracing)
medida de tiempos y optimización (profiling)
pruebas (testing)
Los principales frameworks existentes para AOP en Java son
JBoss AOP
Nanning
Aspectwerkz
AspectJ
De todos ellos el último, AspectJ, es el más maduro y con mayor número de características.
AOP ha experimentado un gran éxito y otros frameworks como Spring Framework han introducido características de la programación orientada a aspectos de una manera más sencilla y en muchos casos transparente para el desarrollador.
Este paradigma se integra dentro de la programación orientada a objetos, y se basa en la utilización de atributos en el código fuente para especificar comportamientos de las clases que normalmente se describen en ficheros de configuración. El objetivo es evitar la dispersión de la información en varios puntos como código fuente y distintos ficheros de configuración.
El origen de este paradigma está en la especificación EJB, que requiere un gran número de ficheros de configuración, clases e interfaces en muchas ocasiones redundantes. Con el fin de facilitar el desarrollo de sistemas EJB se creó XDoclet, que interpretaba una serie de etiquetas JavaDoc especiales y generaba los ficheros redundantes a partir de ellas.
Este paradigma ha sufrido un gran auge a partir de su utilización en el entorno .NET y en estos momentos el mundo Java se ha percatado de su importancia, incluyendo soporte en la nueva especificación Java 5.
AspectJ es una extensión orientada a aspectos del lenguaje de programación Java. Permite la aplicación de aspectos a clases Java para la solución de los problemas cruzados. Un compilador de AspectJ produce ficheros class conformes a la especificación del bytecode de Java, permitiendo que sean ejecutados en cualquier máquina virtual de Java. Al utilizar Java como lenguaje base, AspectJ proporciona todos los beneficios de Java y hace que sea sencillo que los desarrolladores Java entiendan el lenguaje AspectJ.
AspectJ está formado por dos partes: la especificación del lenguaje y la implementación del lenguaje. La parte de especificación del lenguaje define el lenguaje en el que se escribe el código; se implementa la funcionalidad principal con el lenguaje Java y se utilizan las extensiones proporcionadas por AspectJ para implementar el entrelazado (weaving) de los problemas cruzados. La parte de implementación de lenguaje proporciona herramientas para compilar, depurar e integrar AspectJ con los entornos de desarrollo más populares.
En AspectJ la implementación de las reglas de entrelazado (weaving) por el compilador es llamado atajo (crosscutting). Las reglas de entrelazado atajan hacia múltiples módulos de manera sistemática con el objetivo de modularizar los problemas cruzados. AspectJ define dos tipos de crosscutting, crosscutting estático y crosscutting dinámico
crosscutting dinámico
Es el entrelazado de nuevo comportamiento durante la ejecución de un programa. La mayoría de crosscutting que ocurre en AspectJ es dinámico. El crosscutting dinámico aumenta o incluso reemplaza el flujo de ejecución principal del programa de una manera que afecta a los distintos módulos, por lo tanto modificando el comportamiento del sistema. Por ejemplo, se puede especificar que una acción determinada sea ejecutada antes de la ejecución de ciertos métodos o manejadores de excepciones en un conjunto de clases tan sólo especificando en un módulo separado los puntos de entrelazado y la acción a realizar cuando se alcanzan esos puntos.
crosscutting estático
Es el entrelazado de modificaciones en la estructura estática (clases, interfaces y aspectos) del sistema. La aplicación principal del crosscutting estático es dar soporte a la implementación del crosscutting dinámico. Por ejemplo, se pueden añadir nuevos datos y métodos a clases e interfaces para definir estados comportamientos específicos a nivel de clase que pueden ser usados en el crosscutting dinámico. Otro uso del crosscutting estático es declarar advertencias y errores en tiempo de compilación a través de múltiples módulos.
Spring es un framework de aplicaciones Java/J2EE desarrollado por los autores de [JohnsonHoeller04], [TateGehtland04] y [Johnson02], basado en las ideas expuestas en éste último.
Spring proporciona:
Una potente gestión de configuración basada en JavaBeans, aplicando los principios de Inversión de Control (IoC). Esto hace que la configuración de aplicaciones sea rápida y sencilla. Ya no es necesario tener singletons ni ficheros de configuración, una aproximación consistente y elegante. Esta factoría de beans puede ser usada en cualquier entorno, desde applets hasta contenedores J2EE. Estas definiciones de beans se realizan en lo que se llama el contexto de aplicación.
Una capa genérica de abstracción para la gestión de transacciones, permitiendo gestores de transacción enchufables (pluggables), y haciendo sencilla la demarcación de transacciones sin tratarlas a bajo nivel. Se incluyen estrategias genéricas para JTA y un único JDBC DataSource. En contraste con el JTA simple o EJB CMT, el soporte de transacciones de Spring no está atado a entornos J2EE.
Una capa de abstracción JDBC que ofrece una significativa jerarquía de excepciones (evitando la necesidad de obtener de SQLException los códigos que cada gestor de base de datos asigna a los errores), simplifica el manejo de errores, y reduce considerablemente la cantidad de código necesario.
Integración con Hibernate, JDO e iBatis SQL Maps en términos de soporte a implementaciones DAO y estrategias con transacciones. Especial soporte a Hibernate añadiendo convenientes características de IoC, y solucionando muchos de los comunes problemas de integración de Hibernate. Todo ello cumpliendo con las transacciones genéricas de Spring y la jerarquía de excepciones DAO.
Funcionalidad AOP, totalmente integrada en la gestión de configuración de Spring. Se puede aplicar AOP a cualquier objeto gestionado por Spring, añadiendo aspectos como gestión de transacciones declarativa. Con Spring se puede tener gestión de transacciones declarativa sin EJB, incluso sin JTA, si se utiliza una única base de datos en un contenedor web sin soporte JTA.
Un framework MVC (Model-View-Controller), construido sobre el núcleo de Spring. Este framework es altamente configurable vía interfaces y permite el uso de múltiples tecnologías para la capa vista como pueden ser JSP, Velocity, Tiles, iText o POI. De cualquier manera una capa modelo realizada con Spring puede ser fácilmente utilizada con una capa web basada en cualquier otro framework MVC, como Struts, WebWork o Tapestry.
Toda esta funcionalidad puede usarse en cualquier servidor J2EE, y la mayoría de ella ni siquiera requiere su uso. El objetivo central de Spring es permitir que objetos de negocio y de acceso a datos sean reusables, no atados a servicios J2EE específicos. Estos objetos pueden ser reutilizados tanto en entornos J2EE (web o EJB), aplicaciones standalone, entornos de pruebas,... sin ningún problema.
La arquitectura en capas de Spring Figura 6.1, “Spring: arquitectura en capas” ofrece cantidad de flexibilidad. Toda la funcionalidad está construida sobre los niveles inferiores. Por ejemplo se puede utilizar la gestión de configuración basada en JavaBeans sin utilizar el framework MVC o el soporte AOP.
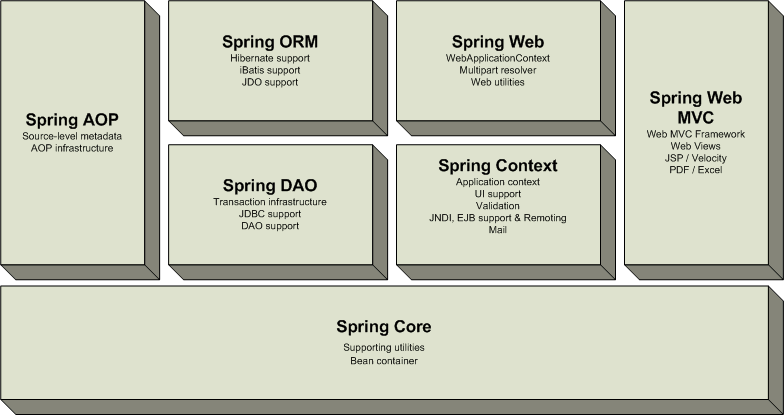
Acegi Security proporciona servicios de seguridad dentro de Spring Framework. Aunque no forma parte directa de Spring está íntimamente ligado con éste.
Proporciona una serie de características clave:
Facilidad de uso
Single Sign On
Proporciona un sistema de autenticación a través del cual los usuarios pueden autenticarse y acceder a múltiples aplicaciones a través de un único punto de entrada. Para ello utiliza el servicio de autenticación CAS (Central Authentication Service) desarrollado por la Universidad de Yale [CAS], con el que una aplicación utilizando Acegi Security puede participar en un entorno single sign on a nivel de toda la empresa. Ya no es necesario que cada aplicación tenga su propia base de datos de autenticación, ni tampoco existe la restricción de que sólo se pueda utilizar dentro del mismo servidor de aplicaciones. Otras características avanzadas que proporciona son soporte para proxy y refresco forzado de logins.
Integración completa en Spring
Utiliza los mecanismos de configuración de Spring
Seguridad a nivel de instancia de objetos del dominio
En muchas aplicaciones es deseable definir listas de control de acceso (Access Control Lists o ACLs) para instancias de objetos del dominio individuales. Proporciona un completo paquete ACL con características que incluyen máscaras de bits, herencia de permisos, un repositorio utilizando JDBC, caché y un diseño pluggable utilizando interfaces.
Configuración no intrusiva
La totalidad del sistema de seguridad puede funcionar en una aplicación web utilizando los filtros que proporciona. No hay necesidad de hacer cambios especiales o añadir librarías al contenedor de Servlets o EJB.
Integración opcional con los contenedores
Las características de autenticación y autorización que proporcionan los contenedores Servlet o EJB pueden ser usadas utilizando los adaptadores que se incluyen. Actualmente existe soporte para los principales contenedores: Catalina (Tomcat), Jetty, JBoss y Resin
Mantiene los objetos libres de código de seguridad
Muchas aplicaciones necesitan proteger datos a nivel de objeto basándose en cualquier combinación de parámetros (usuario, hora del día, autoridad del usuario, método que es llamado, parámetros del método invocado,...). Acegi da esta flexibilidad sin necesidad de añadir código a los objetos de negocio.
Protección de peticiones HTTP
Además de proteger los objetos, el proyecto también permite proteger las peticiones HTTP. Ya no es necesario depender de restricciones de seguridad definidas en el fichero web.xml. Lo mejor de todo es que las peticiones HTTP pueden ser protegidas por una serie de expresiones regulares o expresiones de paths como las utilizadas por Ant, así como autenticación, autorización y gestores de reemplazo de credenciales para la ejecución como otro usuario, todo ello totalmente pluggable.
Seguridad del canal
El sistema de seguridad puede redirigir automáticamente las peticiones a un canal de transmisión adecuado. Comúnmente esto se aplica para asegurar que las páginas seguras estarán sólo disponibles sobre HTTPS, y las páginas públicas sobre HTTP, aunque es suficientemente flexible para soportar cualquier tipo de requisitos de "canal". También soporta combinaciones de puertos no usuales y gestores de decisión de transporte pluggables.
Soporta autenticación HTTP BASIC
Esta autenticación es adecuada para aquellas aplicaciones que prefieren una simple ventana de login del navegador en lugar de un formulario de login. Acegi Security puede procesar directamente peticiones de autenticación HTTP BASIC siguiendo el RFC 1945.
Librería de etiquetas
Proporciona una librería de etiquetas que puede ser utilizada en JSPs para garantizar que contenido protegido como enlaces y mensajes son únicamente mostrados a usuarios que poseen los permisos adecuados.
Configuración mediante el contexto de aplicación de Spring o basada en atributos
Permite seleccionar el método utilizado para la configuración de seguridad del entorno, tanto a través del contexto de aplicación de Spring o utilizando atributos en el código fuente utilizando Jakarta Commons Attributes.
Distintos métodos de almacenamiento de la información de autenticación
Acegi incluye la posibilidad de obtener los usuarios y permisos utilizando ficheros XML, fuentes de datos JDBC o implementando un interfaz DAO para obtener la información de cualquier otro lugar.
Soporte para eventos
Utilizando los servicios para eventos que ofrece Spring, se pueden configurar receptores propios para eventos como login, contraseña incorrecta y cuenta deshabilitada. Esto permite la implementación de sistemas de auditoría y bloqueo de cuentas, totalmente desacoplados del código de Acegi Security.
Caché
Utilizando EHCache o otra implementación propia se puede hacer caché de la información de autenticación, evitando que la base de datos o cualquier otro tipo de fuente de información no sea consultado repetidamente.
Hibernate es un potente mapeador objeto/relacional y servicio de consultas para Java. Es la solución ORM (Object-Relational Mapping) más popular en el mundo Java.
Hibernate permite desarrollar clases persistentes a partir de clases comunes, incluyendo asociación, herencia, polimorfismo, composición y colecciones de objetos. El lenguaje de consultas de Hibernate HQL (Hibernate Query Language), diseñado como una mínima extensión orientada a objetos de SQL, proporciona un puente elegante entre los mundos objetual y relacional. Hibernate también permite expresar consultas utilizando SQL nativo o consultas basadas en criterios.
Soporta todos los sistemas gestores de bases de datos SQL y se integra de manera elegante y sin restricciones con los más populares servidores de aplicaciones J2EE y contenedores web, y por supuesto también puede utilizarse en aplicaciones standalone.
Características clave:
Persistencia transparente
Hibernate puede operar proporcionando persistencia de una manera transparente para el desarrollador.
Modelo de programación natural
Hibernate soporta el paradigma de orientación a objetos de una manera natural: herencia, polimorfismo, composición y el framework de colecciones de Java.
Soporte para modelos de objetos con una granularidad muy fina
Permite una gran variedad de mapeos para colecciones y objetos dependientes.
Sin necesidad de mejorar el código compilado (bytecode)
No es necesaria la generación de código ni el procesamiento del bytecode en el proceso de compilación.
Escalabilidad extrema
Hibernate posee un alto rendimiento, tiene una caché de dos niveles y puede ser usado en un cluster. Permite inicialización perezosa (lazy) de objetos y colecciones.
Lenguaje de consultas HQL
Este lenguaje proporciona una independencia del SQL de cada base de datos, tanto para el almacenamiento de objetos como para su recuperación.
Soporte para transacciones de aplicación
Hibernate soporta transacciones largas (aquellas que requieren la interacción con el usuario durante su ejecución) y gestiona la política optimistic locking automáticamente.
Generación automática de claves primarias
Soporta los diversos tipos de generación de identificadores que proporcionan los sistemas gestores de bases de datos (secuencias, columnas autoincrementales,...) así como generación independiente de la base de datos, incluyendo identificadores asignados por la aplicación o claves compuestas.
XDoclet es un motor de generación de código a partir de plantillas basado en el paradigma de programación orientada a atributos, lo que significa que genera código a partir de metadatos (atributos) añadidos a los ficheros fuente Java.
Para ello utiliza tags JavaDoc especiales, que obtendrá analizando el código fuente, y que servirán para generar otros ficheros como descriptores XML o más código fuente a partir de unas plantillas y los atributos, proporcionando una serie de ventajas:
Reducir el trabajo superfluo
XDoclet permite generar el código redundante a partir de un único punto de información, por ejemplo interfaces EJB a partir de las clases.
Simplificar el desarrollo de aplicaciones J2EE
Permite al desarrollador implementar el enterprise bean y XDoclet genera interfaces, objetos valor, formularios de struts,...
Soporte para los servidores y herramientas más usados
Permite generar ficheros de configuración para los principales servidores de aplicaciones (JBoss, BEA WebLogic, IBM WebSphere, Oracle IAS, Orion, Borland, MacroMedia JRun, Jonas, Pramati, Sybase EAServer) y herramientas (Castor, Hibernate, varias implementaciones JDO, Struts, WebWork, MockObjects).
Extensibilidad
Su diseño modular permite implementar módulos propios para la generación de código a partir de plantillas.
Struts es un framework MVC desarrollado dentro de la Apache Software Foundation que proporciona soporte a la creación de las capas vista y controlador de aplicaciones web basadas en la arquitectura Model2. Está basado en tecnologías estándar como Servlets, JavaBeans y XML.
Struts proporciona un controlador que se integra con una vista realizada con páginas JSP, incluyendo JSTL y Java Server Faces, entre otros. Este controloador evita la creación de servlets y delega en acciones creadas por el desarrollador, simplificando sobremanera el desarrollo de aplicaciones web.
En cuanto a la capa vista, Struts permite utilizar entre otras tecnologías páginas JSP para la realización del interfaz. Para facilitar las tareas comunes en la creación de esta capa existen una serie de tecnologías que se integran con Struts:
Struts taglib, una librería de etiquetas que proporciona numerosa funcionalidad evitando el escribir código Java en las páginas JSP.
JSTL, la librería de etiquetas estándar de Java que añade funcionalidades a la librería de tags de Struts y sustituye alguna de las ya presentes.
Tiles, una extensión que permite dividir las páginas JSP en componentes reusables para la construcción del interfaz.
Struts Validator, proporciona validación de los formularios basándose en reglas fácilmente configurables.
Struts Menú, un proyecto que basándose en un fichero de configuración genera vistosos menús.
CSS, hojas de estilo en cascada, que permite la realización de interfaces web de mayor calidad y separa mejor la presentación de los datos.
JUnit es el standard de facto para realizar los tests de unidad de las aplicaciones Java.
Para completar la funcionalidad ofrecida por JUnit otros proyectos han surgido:
DBUnit
Proyecto que permite realizar tests que involucren una base de datos, insertando datos antes de la ejecución de los tests y comprobando los datos tras ella. También permite importar y exportar los datos desde y hacia ficheros xml o xls (Excel).
JMock
Librería que permite realizar tests utilizando objetos simulados (mock objects) dinámicos. El objetivo es aislar los objetos que se testean sustituyendo los objetos con los que se relacionan por objetos simulados en los que podemos definir su estado y los resultados de los métodos.
StrutsTestCase
Extensión de JUnit que proporciona facilidades para comprobar código basado en Struts utilizando dos posibles implementaciones, una basada en mock objects que no requiere la ejecución dentro de un contenedor de aplicaciones, y otra basada en el proyecto Cactus para la ejecución dentro de un contenedor.
Tras la selección de tecnologías se establece la arquitectura general del sistema que se puede ver en la Figura 6.2, “Arquitectura del sistema”, con las tres capas definidas por el patrón MVC (Model-View-Controller).
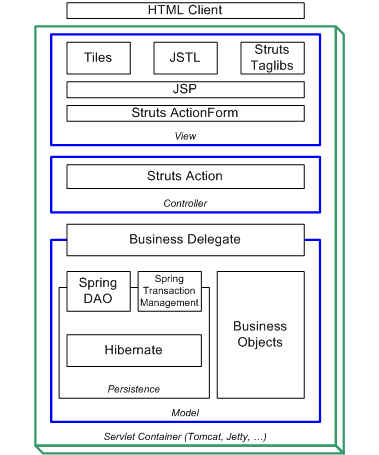
Esta arquitectura se desarrollará durante la primera iteración a la vez que se realiza el prototipo, donde se comprobará su adecuación al desarrollo del sistema.