Tabla de contenidos
Esta fase incluye varias iteraciones sobre el sistema antes de ser entregado. El Plan de Entrega está compuesto por iteraciones de no más de tres semanas. En la primera iteración se puede intentar establecer una arquitectura del sistema que pueda ser utilizada durante el resto del proyecto. Esto se logra escogiendo las historias que fuercen la creación de esta arquitectura, sin embargo, se puede variar con el fin de maximizar el valor de negocio. Al final de la última iteración el sistema estará listo para entrar en producción.
Los elementos que deben tomarse en cuenta durante la elaboración del Plan de la Iteración son: historias de usuario no abordadas, velocidad del proyecto, pruebas de aceptación no superadas en la iteración anterior y tareas no terminadas en la iteración anterior.
En esta iteración se contempla la realización del prototipo que además de servir para evaluar la tecnología también establecerá la arquitectura base del sistema.
Las historias de usuario a abordar se pueden ver en la Tabla 8.1, “Historias primera iteración”.
Tabla 8.1. Historias primera iteración
| Funcionalidad común | 2 |
| Auditoría | 2 |
| Creación de contactos | 1 |
| Visualización, modificación, eliminación y búsqueda de contactos | 2 |
| ESTIMACIÓN INICIAL | 7 |
| REAL | 9 |
Para comenzar el desarrollo es necesario configurar una estructura de directorios adecuada que facilite las tareas. Utilizando Maven esto no supone un gran problema ya que para cada proyecto se tiene una estructura bien definida, con lo que nos debemos centrar en la correspondencia entre nuestro proyecto y sus módulos en proyectos Maven, teniendo en cuenta que una de las principales filosofías de Maven es la de que cada proyecto genere un único artefacto, que es así como llama a los ficheros jar, war,...
Con el objeto de fomentar la reusabilidad el código se separará en módulos basándose en funcionalidad, y dentro de cada módulo se creará un subproyecto para la capa modelo y otro para el interfaz web, que agrupará las capas controlador y vista.
Para auditar los cambios que se realizan a los datos del sistema es necesario saber una serie de datos según el tipo de operación que se realice:
creación
Cuando un nuevo objeto es creado, se debe saber quién lo ha creado y cuándo.
modificación
Cuando se modifica un objeto es necesario saber quién lo ha modificado y cuándo, y además guardar la versión anterior por si fuera necesario restaurarlo.
borrado
Al borrar un objeto se necesita saber quién lo ha borrado y cuándo, y también se debe guardar por si se necesitara restaurar.
De todo lo anterior se deduce que una buena forma de permitir la auditoría es guardar la fecha de creación de un objeto cuando se crea, la de eliminación cuando se borra y el usuario que lo ha creado y borrado respectivamente. A partir de la fecha de borrado o usuario que lo ha borrado, se podrá determinar si un objeto está eliminado o no.
El problema surge con la modificación de objetos, con lo que la aproximación anterior se completa de la siguiente manera: cuando un objeto es modificado se marcará como borrado con fecha de eliminación y autor, y se creará un nuevo objeto que tendrá las mismas propiedades que el objeto modificado, con fecha de creación y autor.
Con esta aproximación lo que se consideraría identificador del objeto pasaría a representar una única versión del objeto, siendo necesaria otra propiedad que nos permita relacionar entre sí todas las versiones del objeto, lo que se llamará código (code). Todas las versiones de un mismo objeto tendrán el mismo código pero cada una con su identificador único, y se podrá seguir la evolución desde su creación hasta su borrado mediante este código y las fechas de creación y eliminación.
Al tratar con información temporal deben tratarse dos dimensiones [Fowler]:
momento en el que la información cambia (transaction time o record time)
momento en el que la información es efectiva (valid time o actual time)
En el caso de la auditoría la definición aplicable es la primera, y se utilizará el nombre transaction time para referirse al rango de fechas que comienza en el momento en el que un dato es introducido en el sistema y finaliza cuando este dato deja de ser relevante y es borrado. Este rango de fechas será limitado cuando el objeto esté eliminado o esa versión haya sido modificada, y tendrá su final en el infinito mientras el objeto siga siendo válido.
En el módulo common se irán añadiendo las funcionalidades que se prevé serán utilizadas por más de un módulo para facilitar su reusabilidad.
Dado que la url en la que se encuentra el sitio web es http://oness.sourceforge.net (o también http://oness.sf.net), el paquete base de Java será net.sf.oness, escogiéndose la segunda url por ser más breve y más común entre otros proyectos alojados en Sourceforge utilizar sf en lugar de sourceforge para la nomenclatura de los paquetes. A partir de este paquete base se crearán uno por cada módulo, en este caso, el paquete base para la funcionalidad común será net.sf.oness.common.
En una primera aproximación se diferencian claramente tres tipos de funcionalidades comunes según a la capa de la aplicación que afectarán:
all
Funcionalidad que afectará a la totalidad del sistema.
model
Funcionalidad que afectará tan sólo a la capa modelo del sistema.
webapp
Funcionalidad que afectará sólo a las capas vista y controlador de las aplicaciones web.
Cada submódulo de los anteriores se corresponderá con un paquete, net.sf.oness.common.all, net.sf.oness.common.model y net.sf.oness.common.webapp respectivamente.
Es necesario extraer ciertas tareas repetitivas que serán comunes a gran parte de las clases Java. Se diferencian dos objetivos claros: facilitar el depurado (logging y tracing) e implementación de métodos definidos en el contrato Java (toString, equals, hashCode y clone).
Este es uno de los campos típicos donde se aplica la Programación Orientada a Aspectos [Laddad03], que nos proporciona los mecanismos para implementar esta funcionalidad de una manera sencilla. El objetivo es mostrar las llamadas a los métodos con sus parámetros, la finalización de estas llamadas y las excepciones que ocurren durante la ejecución.
La tecnología que mejor se adapta es AspectJ, desarrollando un aspecto que se aplique a todas las clases y que pueda deshabilitarse tras la fase de desarrollo de una forma sencilla. También debe permitirse el filtrado de los mensajes de logging a nivel de clase, paquete o tipo de mensaje (entrada de método, salida de método o lanzamiento de excepciones). Para ello este aspecto deberá utilizar un framework como Apache Commons Logging que proporciona una capa de abstracción sobre otros sistemas de logging que pueden ser configurados declarativamente, como Log4J, que será el usado normalmente por su sencillez de configuración y potencia de uso
El aspecto desarrollado LoggingAspect es totalmente genérico y aplicable a cualquier sistema. Algunas consideraciones que ha sido necesario tener en cuenta son:
precedencia
el aspecto de logging debe tener mayor precedencia que otros aspectos para que los mensajes de entrada en un método se ejecuten antes que cualquier otro aspecto que se ejecute antes de la ejecución de un método, y los mensajes de salida después de los otros aspectos que se ejecuten después de la ejecución de un método.
evitar la recursividad infinita
no se debe hacer logging del propio aspecto así como tampoco de las ejecuciones que tienen lugar dentro de los métodos llamados por él, principalmente el método toString que puede ser llamado implícitamente por la máquina virtual al hacer operaciones con strings y objetos.
La implementación de estos métodos aunque no es siempre imprescindible suele ser deseable, y supone una tarea tediosa que hay que realizar en cada clase que se implementa. Para facilitar o incluso evitar esta tarea se crea una clase que hará de raíz de la jerarquía de clases siempre que sea posible, implementando de manera genérica los métodos toString, equals, hashCode y clone haciendo uso extensivo de los metadatos que proporciona Java a través del API reflection. Para facilitar este trabajo ya existen proyectos de la ASF, principalmente los proyectos commons-lang y commons-beanutils.
toString, equals y hashCode son implementados utilizando commons-lang de manera que se utilizan todas sus propiedades para mostrar de manera homogénea el estado del objeto, hacer comparaciones entre objetos o calcular su código hash, respectivamente.
clone es implementado usando commons-beanutils, que proporciona una manera sencilla de clonar superficialmente un objeto copiando todas sus propiedades.
Como soporte a la auditoría se creará el paquete auditing, creándose en primer lugar un interfaz Auditable que deben implementar aquellos objetos que pretendan ser auditados. Tal y como se mencionó en “Auditoría”, aquellos objetos auditables deben tener:
identificador (id)
código (code)
fechas de transacción (transactionTime)
creado-por (createdBy)
borrado-por (deletedBy)
Junto con este interfaz se crea una implementación por defecto AbstractAuditableObject de la que pueden heredar otras clases.
Se seguirá en patrón Business Object [AlurCrupiMalks03] para reflejar el modelo conceptual del dominio. Estos objetos del dominio serán persistidos mediante Hibernate, por lo que es necesario afinar los métodos definidos en BaseObject, lo que se hará en la clase AbstractBusinessObject, debido a que Hibernate puede utilizar una caché perezosa para cargar las colecciones, con lo que los métodos toString, equals y hashCode definidos en la superclase se sobrecargarán para ignorar colecciones. El método clone debe ser también sobrecargado para evitar que una colección sea referenciada por dos objetos distintos, restricción que impone Hibernate y que se soluciona creando una nueva colección pero con los mismos objetos.
Para facilitar la implementación de los tests, principalmente en cuestiones relacionadas con la integración del framework Spring, se han realizado unas clases utilidad.
SpringApplicationContext
Una clase que proporciona métodos estáticos para acceder al contexto de aplicación de Spring desde los tests.
SpringDatabaseExport
Una utilidad para exportar una base de datos a partir de una fuente de datos definida en el contexto de aplicación de Spring.
SpringDatabaseTestCase
Una clase base para los tests que integra DBUnit con Spring, permitiendo que DBUnit utilice una fuente de datos definida en el contexto de aplicación de Spring.
Para acceder a los datos se utilizará el patrón DAO (Data Access Object [AlurCrupiMalks03]) que ocultará la implementación utilizada por si se diera la necesidad de cambiarla en el futuro. Dado que la persistencia será gestionada en principio con Hibernate, que permite el acceso a gran cantidad de metadatos, se intentará realizar un DAO genérico que proporcione los servicios de persistencia para cualquier clase sin necesidad de escribir más líneas de código.
Se usará también el soporte que proporciona Spring para la integración con Hibernate, concretamente la clase HibernateDaoSupport. Se implementará un DAO genérico, HibernateDao, con las siguientes operaciones típicas:
findById obtener un objeto a partir de su identificador
create crear un objeto persistente
update actualizar un objeto persistente
delete no se implementará por no ser necesario ya que los datos no se borrarán nunca de la base de datos por cuestiones de auditabilidad.
Dado que el DAO será genérico es necesario pasarle la clase a la que proporcionará persistencia en el momento de su creación.
Para ocultar detalles de implementación se crearán dos interfaces:
FinderDao
Este interfaz contendrá aquellos métodos de sólo lectura que permitirán realizar búsquedas en las base de datos, comenzando con find, un método que implementa la búsqueda por criterio, es decir a partir de un objeto con algunas propiedades encuentra todos aquellos con propiedades coincidentes. Utilizando el patrón Value List Handler [AlurCrupiMalks03] no devolverá todos los objetos que cumplan el criterio sino sólo un número determinado, en forma de PaginatedList, que representa un rango de objetos dentro de una lista.
Dao
Interfaz de conveniencia que extiende AuditingDao (ver “Auditoría”) y FinderDao.
La configuración dentro del contexto de aplicación de Spring se puede ver en el fichero applicationContext-oness-common-model.xml, donde está centralizada para todo el sistema.
Ejemplo 8.1. Configuración general de Hibernate
<!-- Session Factory -->
<bean id="sessionFactory"
class="org.springframework.orm.hibernate.LocalSessionFactoryBean">
<property name="dataSource">
<ref bean="dataSource" />
</property>
<property name="mappingResources">
<ref bean="mappingResources" />
</property>
<property name="hibernateProperties">
<ref bean="hibernateProperties" />
</property>
</bean>
<!-- Transaction manager for a single Hibernate SessionFactory
(alternative to JTA) -->
<bean id="transactionManager"
class="org.springframework.orm.hibernate.HibernateTransactionManager">
<property name="sessionFactory">
<ref local="sessionFactory" />
</property>
</bean>En este fichero se establece la configuración general de Hibernate aplicable a todos los módulos, el sessionFactory y el gestor de transacciones. Se delega en los contextos de aplicación de cada módulo para la configuración concreta, así se centraliza y se evita la replicación de estos parámetros. En concreto se espera que cada módulo defina un bean llamado mappingResources que por ejemplo podría ser algo como esto:
Ejemplo 8.2. Configuración del fichero de mapeo de Hibernate de Party
<bean id="mappingResources" class="java.util.ArrayList">
<constructor-arg>
<list>
<value>net/sf/oness/party/model/party/bo/Party.hbm.xml</value>
</list>
</constructor-arg>
</bean>También se evita la definición de los beans dataSource e hibernateProperties para permitir utilizar indistintamente un dataSource local usando por ejemplo commons-DBCP o uno obtenido mediante JNDI, útil en servidores de aplicaciones J2EE. Tan sólo es necesario definir en tiempo de ejecución cuál de los siguientes ficheros se añaden al contexto de aplicación:
applicationContext-oness-common-model-dataSource-dbcp.xml
Útil para la ejecución de los tests fuera de un servidor J2EE. Las propiedades concretas, definidas como ${...}, no están en este fichero, sino en dataSource.properties que se obtiene del classpath, de esta forma no es necesario modificarlo, sino que simplemente se puede añadir otro fichero con el mismo nombre en el classpath antes que él y tendrá mayor precedencia. En caso de que alguna de las propiedades exista como propiedades del sistema también tendrán mayor precedencia, lo que es de gran utilidad a la hora de ejecutar los tests con Maven, ya que sin necesidad de cambiar o crear ningún fichero se podrán ejecutar los tests en cualquier sistema gestor de bases de datos en cualquier máquina.
Ejemplo 8.3. Configuración de la fuente de datos DBCP
<!-- Get datasource properties from file --> <bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"> <property name="location"> <value>classpath:dataSource.properties</value> </property> <!-- Override properties in file with system properties --> <property name="systemPropertiesModeName"> <value>SYSTEM_PROPERTIES_MODE_OVERRIDE</value> </property> </bean> <!-- DBCP Basic datasource --> <bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"> <property name="driverClassName"> <value>${dataSource.driverClassName}</value> </property> <property name="url"> <value>${dataSource.url}</value> </property> <property name="username"> <value>${dataSource.username}</value> </property> <property name="password"> <value>${dataSource.password}</value> </property> </bean> <!-- Hibernate properties --> <bean id="hibernateProperties" class="net.sf.oness.common.model.dao.hibernate.HibernateProperties"> <constructor-arg> <props> <prop key="hibernate.dialect">${hibernate.dialect}</prop> <prop key="hibernate.show_sql">${hibernate.show_sql}</prop> <prop key="hibernate.hbm2ddl.auto">${hibernate.hbm2ddl.auto}</prop> </props> </constructor-arg> </bean>dataSource.properties utilizadas normalmente:
applicationContext-oness-common-model-dataSource-jndi.xml
Útil para la ejecución en servidores J2EE como Tomcat. Permite ejecutar la aplicación sin necesidad de modificar el fichero war distribuido, ya que la configuración de los parámetros necesarios se realiza en el contenedor.
Ejemplo 8.5. Configuración de la fuente de datos JNDI
<!-- JNDI DataSource for J2EE environments --> <bean id="dataSource" class="org.springframework.jndi.JndiObjectFactoryBean"> <property name="jndiName"> <value>java:comp/env/jdbc/oness</value> </property> </bean> <!-- Hibernate Dialect --> <bean id="hibernateDialect" class="org.springframework.jndi.JndiObjectFactoryBean"> <property name="jndiName"> <value>java:comp/env/net.sf.oness.common.model.hibernateDialect</value> </property> </bean> <!-- Hibernate properties --> <bean id="hibernateProperties" class="net.sf.oness.common.model.dao.hibernate.HibernateProperties"> <constructor-arg> <props> <prop key="hibernate.show_sql">false</prop> <prop key="hibernate.hbm2ddl.auto">create</prop> </props> </constructor-arg> <property name="hibernateDialect"><ref local='hibernateDialect'/></property> </bean>La configuración concreta para el servidor Tomcat, utilizando el módulo party como ejemplo, se especifica a continuación. Tan sólo algunas propiedades (en negrita) necesitan ser modificadas para utilizar otro sistema gestor de base de datos u otra máquina como servidor.
Ejemplo 8.6. Configuración de la aplicación web party-webapp en Tomcat utilizando JNDI
<!-- To setup this context copy this file to the specified directory and change it to match your needs. You may rename it if you want. o Tomcat 4: TOMCAT_HOME/webapps o Tomcat 5: TOMCAT_HOME/conf/Catalina/localhost --> <Context path="/oness-party-webapp" docBase="${catalina.home}/webapps/oness-party-webapp.war" debug="99" reloadable="true"> <!-- To use a global jndi datasource uncomment the <ResourceLink> tag and move the other entries to your server.xml under <GlobalNamingResources> --> <!-- <ResourceLink name="jdbc/oness" global="jdbc/oness" type="javax.sql.DataSource"/> --> <Environment description="Hibernate dialect" name="net.sf.oness.common.model.hibernateDialect" value="net.sf.hibernate.dialect.MySQLDialect" type="java.lang.String"/> <Resource name="jdbc/oness" auth="Container" type="javax.sql.DataSource"/> <ResourceParams name="jdbc/oness"> <parameter> <name>factory</name> <value>org.apache.commons.dbcp.BasicDataSourceFactory</value> </parameter> <!-- Maximum number of dB connections in pool. Make sure you configure your mysqld max_connections large enough to handle all of your db connections. Set to 0 for no limit. --> <parameter> <name>maxActive</name> <value>100</value> </parameter> <!-- Maximum number of idle dB connections to retain in pool. Set to 0 for no limit. --> <parameter> <name>maxIdle</name> <value>30</value> </parameter> <!-- Maximum time to wait for a dB connection to become available in ms, in this example 10 seconds. An Exception is thrown if this timeout is exceeded. Set to -1 to wait indefinitely. --> <parameter> <name>maxWait</name> <value>10000</value> </parameter> <!-- MySQL dB username and password for dB connections --> <parameter> <name>username</name> <value></value> </parameter> <parameter> <name>password</name> <value></value> </parameter> <!-- Class name for JDBC driver --> <parameter> <name>driverClassName</name> <value>com.mysql.jdbc.Driver</value> </parameter> <!-- Autocommit setting. This setting is required to make Hibernate work. Or you can remove calls to commit(). --> <parameter> <name>defaultAutoCommit</name> <value>false</value> </parameter> <!-- The JDBC connection url for connecting to your MySQL dB. The autoReconnect=true argument to the url makes sure that the mm.mysql JDBC Driver will automatically reconnect if mysqld closed the connection. mysqld by default closes idle connections after 8 hours. --> <parameter> <name>url</name> <value>jdbc:mysql://localhost/test</value> </parameter> <!-- Recover abandoned connections --> <parameter> <name>removeAbandoned</name> <value>true</value> </parameter> <!-- Set the number of seconds a dB connection has been idle before it is considered abandoned. --> <parameter> <name>removeAbandonedTimeout</name> <value>60</value> </parameter> <!-- Log a stack trace of the code which abandoned the dB connection resources. --> <parameter> <name>logAbandoned</name> <value>true</value> </parameter> </ResourceParams> </Context>

En este apartado se implementará lo definido en “Auditoría”, creando un aspecto que intercepte las llamadas a los DAOs de la siguiente manera:
create
Antes de crear el objeto persistente se establecería el inicio de la fecha de transacción al momento actual y el final a infinito.
delete
Se sustituye la llamada al método delete del DAO por una llamada a update tras poner el final de la fecha de transacción al momento actual.
update
Se sustituye la llamada al método update del DAO por dos llamadas, una a update para marcar como borrado el objeto anterior y otra a create para crear la nueva versión.
En principio este aspecto se ha implementado con AspectJ, pero posteriormente se ha implementado mediante el soporte AOP de Spring dado que la primera opción requería utilizar el compilador de AspectJ y la segunda permite una integración más fácil dado que no modifica el bytecode java, sino que utiliza proxies dinámicos.
AuditableDaoAdvisor
Este es el aspecto que interceptará las llamadas a los DAOs y las delegará a AuditingDaoHelper.
AuditingDaoHelper
En esta clase se implementan las reglas mencionadas anteriormente que se ejecutarán cada vez que se intercepte una llamada.
Para dar soporte se añaden los siguientes interfaces:
AuditableDao
Interfaz con los métodos necesarios que debe implementar un DAO para permitir la auditoría (findById, create y update).
AuditingDao
Este interfaz extiende AuditableDao y añade el método delete.
Para facilitar la utilización de fechas y rangos de fechas se crean las clases:
Date
Encapsula la clase Calendar de Java truncando su precisión normalmente al segundo ya que no es necesario más ni es soportada por muchas bases de datos, y añade nuevas funcionalidades. Se definen dos constantes MIN_VALUE y MAX_VALUE que representan respectivamente el infinito negativo y positivo.
DateRange
Está formada por un Date inicial y uno final y añade métodos para trabajar con rangos de fechas (inclusión, duración,...).
Para poder persistir estas clases con Hibernate como componentes y poder reutilizarlas es necesario implementar unos interfaces:
DateType
Persiste Date implementando UserType.
DateRangeType
Persiste DateRange implementando CompositeUserType. Principalmente se transforman las constantes MIN_VALUE y MAX_VALUE a valores null en SQL.
La configuración del aspecto se realiza dentro del contexto de aplicación de Spring en el fichero applicationContext-oness-common-model.xml para que esté disponible para todos los módulos del sistema.
Ejemplo 8.7. Configuración del aspecto de auditoría en Spring
<!-- AuditingDao AOP -->
<bean id="autoProxyCreator"
class="org.springframework.aop.framework.autoproxy.DefaultAdvisorAutoProxyCreator">
</bean>
<bean id="auditingDaoAdvisor"
class="net.sf.oness.common.model.dao.AuditableDaoAdvisor">
</bean>Se utiliza la funcionalidad de creación automática de proxies de Spring para que el aspecto se aplique automáticamente a todos aquellos beans definidos en el contexto de aplicación que cumplan el contrato establecido por el método matches del aspecto.
Detro de este paquete se puede encontrar una implementación del interfaz List del api collections de Java que proporciona una manera de tratar listas paginadas, aquellas en las que normalmente sólo se accede a una pequeña porción, tal y como se define en el patrón ValueListHandler [AlurCrupiMalks03].
También se incluye DatabasePopulator, una clase que configurada desde el contexto de aplicación de Spring permite importar datos de un fichero de DBUnit tanto en formato xml como xls (Excel) en la base de datos. Se utilizará para insertar los datos de ejemplo para las demostraciones.
Para no tener que implementar una acción de Struts para cada acción de la vista se utilizarán DispatchActions que permitirán utilizar una única clase para varias urls de peticiones, agrupando también la funcionalidad relacionada. Para facilitar la utilización se creará una acción AutoDispatchAction que basándose en la url de la petición escogerá automáticamente el método que debe ser llamado, por ejemplo urls del tipo create* o update* provocarán llamadas a los métodos create o update respectivamente.
Para integrar Spring con Struts y poder acceder al contexto de aplicación de donde se obtendrá la correspondiente fachada de la capa modelo se añade también la clase SpringActionSupport que permite obtener de manera sencilla cualquier objeto del contexto de aplicación de Spring.
Los tests de unidad deben comprobar porciones de código lo más pequeñas posible y de forma aislada, por lo que será necesario utilizar mock objects que sustituyan la fachada de la capa modelo para aislarla de esta forma de la capa controlador. Se utilizará con este fin el framework JMock, que proporciona una solución basada en mocks dinámicos mucho más eficiente en el desarrollo que soluciones estáticas que requieren la generación de código fuente. Por otro lado también es necesario probar las acciones de Struts aisladamente sin necesidad de ejecutarlas en un contenedor, para lo que se ajusta el proyecto StrutsTestCase, una extensión de JUnit. Para poder integrar ambas aproximaciones, JMock y StrutsTestCase, es necesario introducir una nueva clase JMockStrutsTestCase de la que extenderán los tests concretos.
Posteriormente este módulo ha sido movido a common-webapp-controller al crear los nuevos módulos common-webapp-view y common-webapp-taglib en la segunda iteración.
Comenzamos con los objetos del dominio que surgen en las historias relativas a los contactos y se realiza el diagrama UML que se puede ver en la Figura 8.1, “Creación, visualización, modificación, eliminación y búsqueda de contactos” para el diseño de la capa modelo.
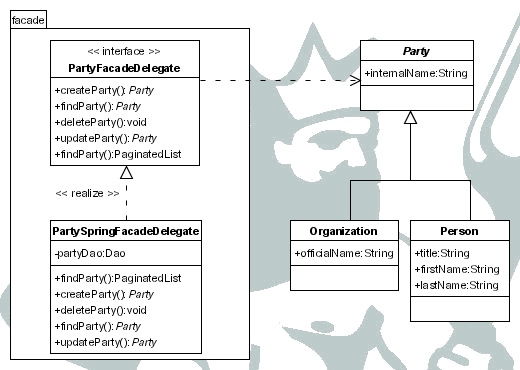
Como se puede ver se tratan los conceptos de
party: representa un contacto
person: aquellos contactos que son personas
title: título (Sr., Sra.)
firstName: nombre
lastName: apellidos
organization: aquellos contactos que son organizaciones
officialName: nombre oficial
Como interfaz de la capa modelo hacia capas superiores dentro de la arquitectura MVC se crea la fachada (façade) o servicio PartyFacade para ocultar los detalles de implementación de la capa modelo, desempeñando el papel de los patrones SessionFacade y BusinessDelegate [AlurCrupiMalks03].
Para gestionar la persistencia de estos objetos se etiquetan los ficheros fuente con atributos XDoclet que serán procesados mediante el plugin XDoclet de Maven para generar los ficheros de configuración de Hibernate que especifican para cada clase cómo se mapearán esos objetos en el sistema gestor de bases de datos.
Por ejemplo para la clase Party
Ejemplo 8.9. Definición de atributos de persistencia en la clase Party
/**
* Value object for Party.
*
* The subclasses MUST override the getType() method
*
* @hibernate.class table="party"
*
* @hibernate.discriminator column="type"
*
* @author Carlos Sanchez
*/
public class Party extends AbstractBusinessObject {La línea en negrita especifica que los objetos de esta clase serán persistidos en la tabla party en la base de datos.
Ejemplo 8.10. Definición de atributos de persistencia en los métodos de la clase Party
/**
* @hibernate.property
*
* @return String
*/
public String getInternalName() {
return this.internalName;
}
public void setInternalName(String internalName) {
this.internalName = internalName;
}En este caso la línea en negrita define que la propiedad internalName es persistente, con lo que la tabla en la base de datos tendrá una columna para guardar sus valores.
En cuanto a la fachada será necesaria una implementación del interfaz PartyFacadeDelegate que utilice Spring, PartySpringFacadeDelegate. Es una buena práctica crear un interfaz para que los detalles de implementación queden ocultos a las otras capas. Entre estos detalles de implementación se encuentra una nueva propiedad, partyDao, y los métodos necesarios para acceder a ella, getPartyDao y setPartyDao. Esta propiedad contendrá el DAO responsable de la persistencia de la clase Party y sus subclases y será inicializado por Spring a partir del contexto de aplicación.
Cada uno de los métodos de la fachada debe ejecutarse en una transacción, lo que se puede configurar en el contexto de aplicación de Spring, que se puede ver en el Ejemplo 8.11, “Configuración de la fachada y los DAOs de party”.
Ejemplo 8.11. Configuración de la fachada y los DAOs de party
<!-- ======================= PERSISTENCE DEFINITIONS ======================== --> <bean id="mappingResources" class="java.util.ArrayList"><constructor-arg> <list> <value>net/sf/oness/party/model/party/bo/Party.hbm.xml</value> </list> </constructor-arg> </bean> <!-- DAO objects: Hibernate implementation --> <bean id="partyDao" class="net.sf.oness.common.model.dao.hibernate.HibernateDao">
<constructor-arg> <value>net.sf.oness.party.model.party.bo.Party</value> </constructor-arg> <property name="sessionFactory"> <ref bean="sessionFactory" /> </property> </bean> <!-- =============================== FACADE ================================ --> <!-- Party Facade --> <bean id="partyFacadeDelegate" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<property name="transactionManager"> <ref bean="transactionManager" /> </property> <property name="target"> <ref local="partyTarget" /> </property> <property name="transactionAttributes"> <props> <prop key="get*">readOnly</prop> <prop key="find*">readOnly</prop> <prop key="edit*">readOnly</prop> <prop key="create*">PROPAGATION_REQUIRED,ISOLATION_SERIALIZABLE</prop> <prop key="update*">PROPAGATION_REQUIRED,ISOLATION_SERIALIZABLE</prop> <prop key="delete*">PROPAGATION_REQUIRED,ISOLATION_SERIALIZABLE</prop> </props> </property> </bean> <!-- PartyTarget primary business object implementation --> <bean id="partyTarget" class="net.sf.oness.party.model.facade.PartySpringFacadeDelegate">
<property name="partyDao"> <ref local="partyDao" /> </property> </bean>
La aplicación web actuará como interfaz del modelo anteriormente creado. Se divide en dos partes: controlador y vista, que serán implementadas utilizando Struts, Tiles, JSP, JSTL y CSS.
Se incluye un fichero de configuración para Tomcat, ya listado anteriormente en el Ejemplo 8.6, “Configuración de la aplicación web party-webapp en Tomcat utilizando JNDI”, que permite configurar la aplicación vía JNDI sin necesidad de modificar el fichero war.
El controlador constará de la clase PartyAction, que gestionará todas aquellas acciones que realice el usuario a través de la vista y las transformará en llamadas a la fachada de la capa modelo.
create: crear un contacto
update: actualizar un contacto
find: buscar un contacto por sus atributos
show: mostrar un contacto concreto
edit: mostrar un contacto para su posterior posible actualización
delete: borrar un contacto
La vista estará formada por las páginas JSP, los mensajes de la aplicación y los ficheros de configuración.
Interfaz web
Utilizando Tiles es posible utilizar una aproximación basada en componentes para realizar el interfaz web, separando las páginas JSP en porciones reutilizables que se ensamblarán en los ficheros de configuración de Tiles mediante definiciones.
Menús de la aplicación
Páginas JSP necesarias para proporcionar la funcionalidad de gestión de contactos.
details.jsp: muestra los detalles de un contacto.
form.jsp: que se utiliza tanto para crear o editar un contacto como para buscar por sus atributos.
list.jsp: muestra una lista de contactos, resultado de una búsqueda.
Páginas de soporte: cabecera, pie de página, menús,...
Mensajes
Para permitir la internacionalización de la aplicación se utiliza el soporte que proporciona JSTL. A cada mensaje se le asigna una clave que es la que se utiliza en las páginas JSP y en ficheros de texto, uno por idioma, se escriben las correspondencias entre clave y mensaje.
Configuración
Descriptor de aplicaciones web
Ubicación de los mensajes para JSTL
Ubicación de los ficheros de configuración de Spring
Acciones y formularios de struts
Validación de los formularios de struts
Definiciones de tiles
Menús de struts-menu